
Automatic Smart Data Cleaning
Automatically detect anomalies and data quality issues using AI-assisted and rule-based methods to improve dataset reliability.
DataIndy empowers data teams to accelerate insights by automating the first mile of data integration using deterministic and AI-driven algorithms, with quality, governance, and compliance by design.
DataIndy is a GDPR-compliant, cloud-native SaaS platform that streamlines the entire data lifecycle, from cleaning and normalizing messy files to advanced analytics, data warehousing/lakehouse, and dashboarding, with governance and compliance built in by design.
Its multi-tenant architecture supports data factory and data mesh initiatives for both SMBs and enterprises, enforcing standards and automating governance at scale.
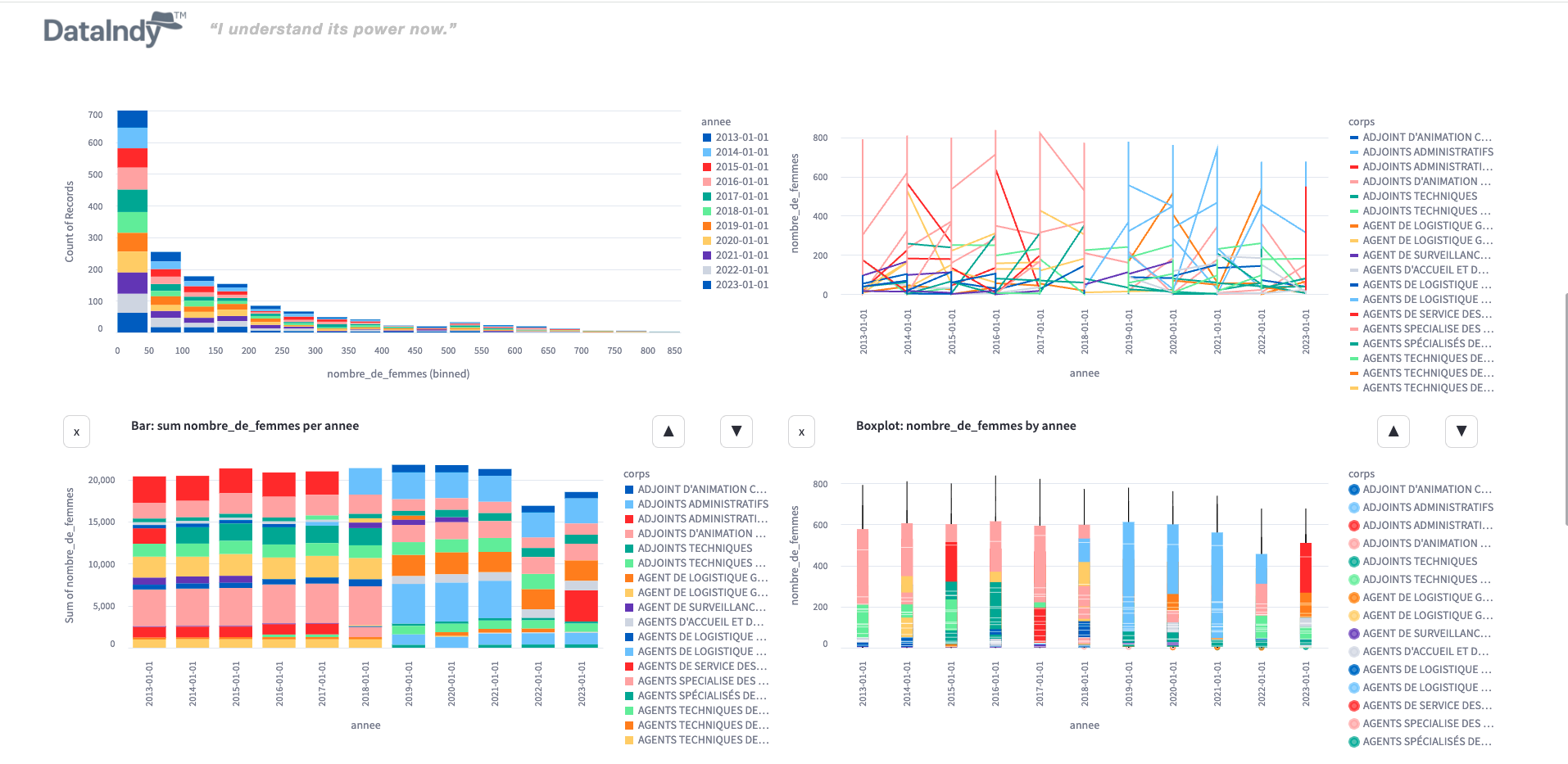
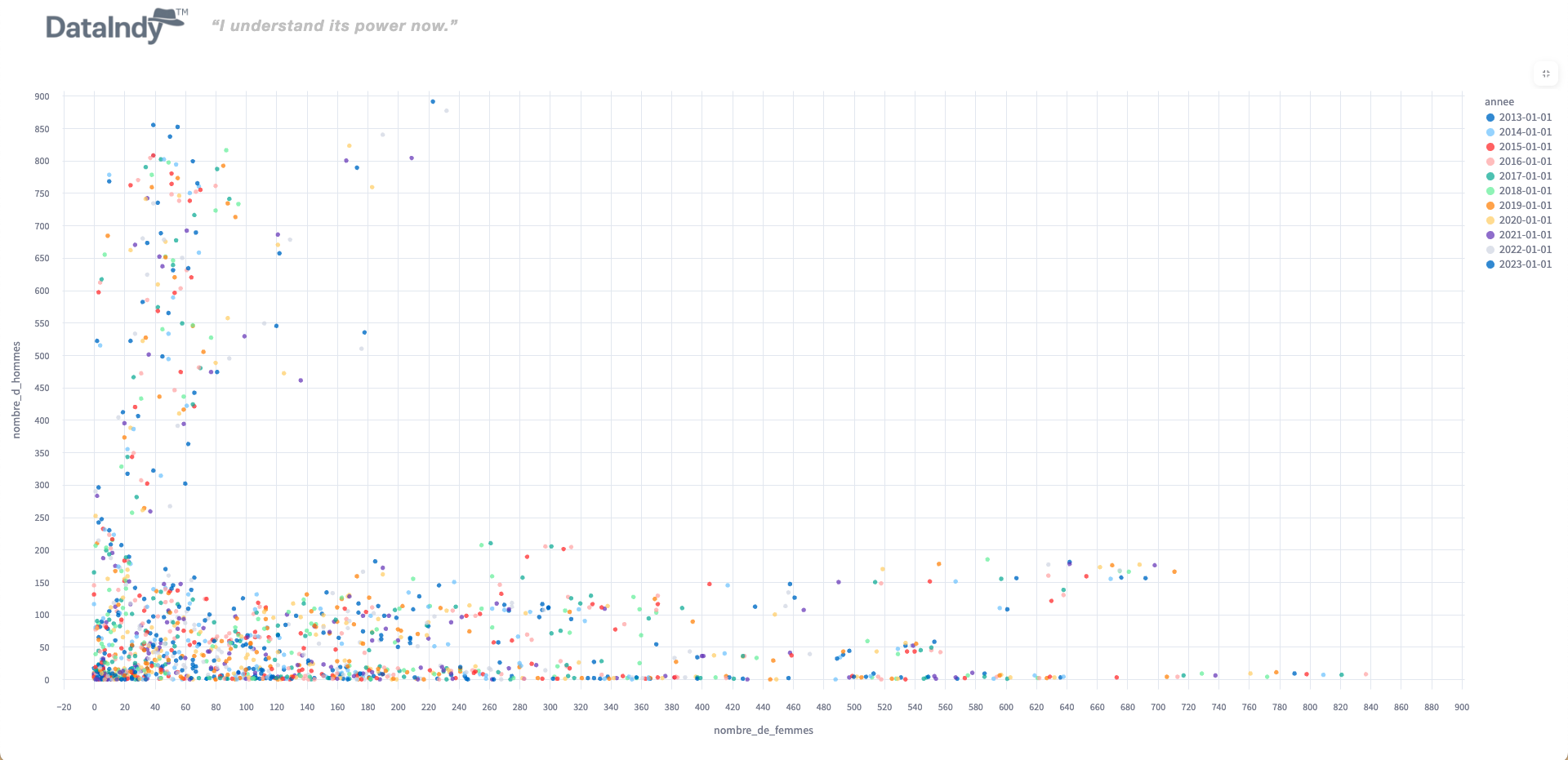
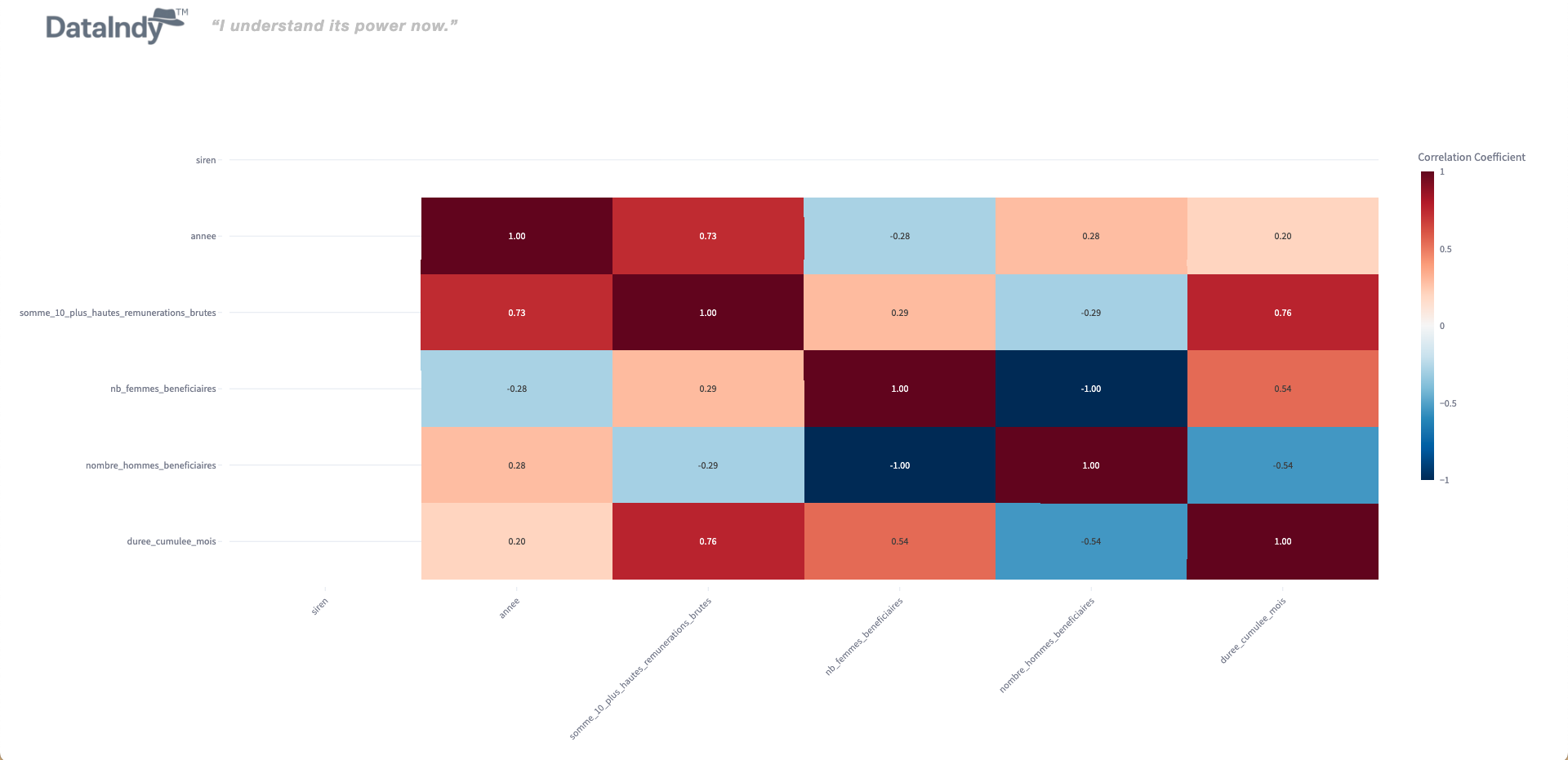

Automatically detect anomalies and data quality issues using AI-assisted and rule-based methods to improve dataset reliability.
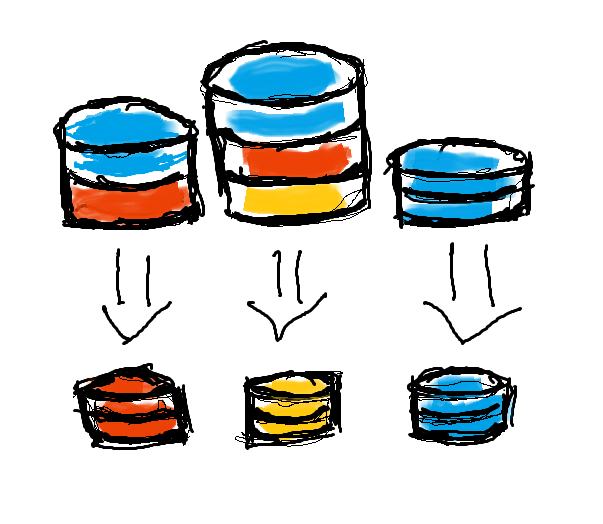
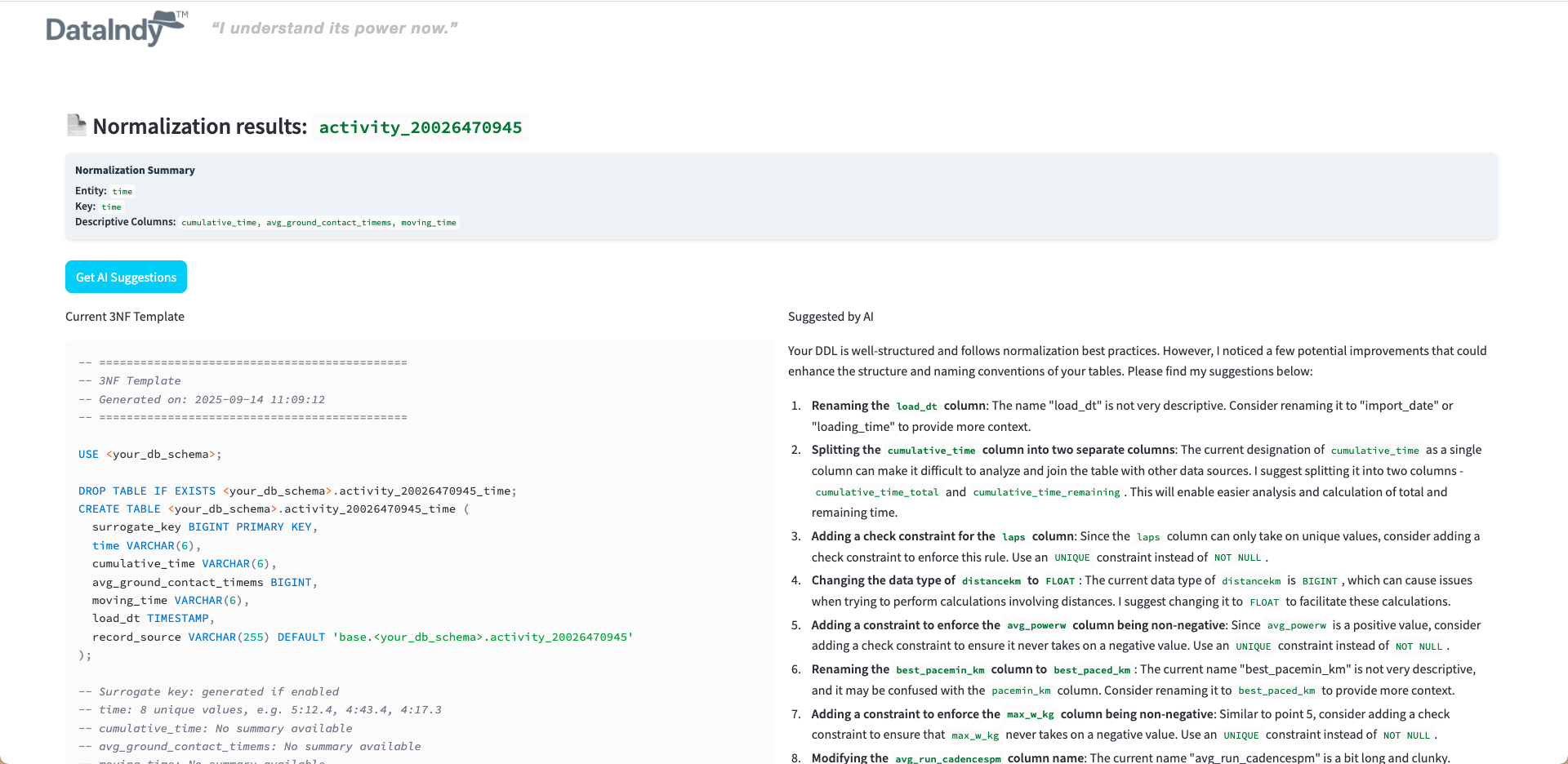
Profile and transform datasets into normalized models efficiently, preparing them for analytics and downstream modeling.
Run multiple pipelines and let DataIndy automatically select the best-performing model based on evaluation metrics.

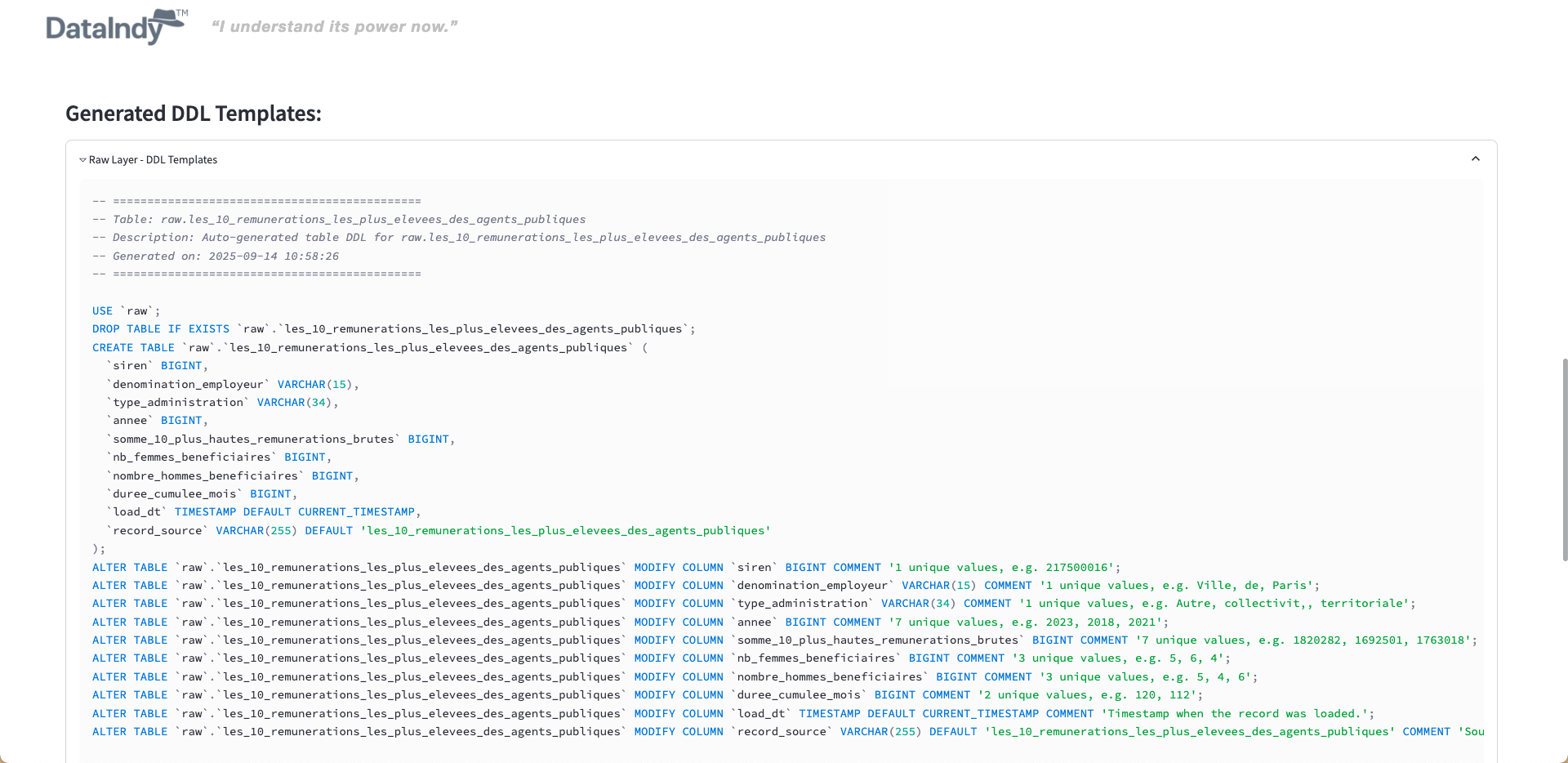
Automatically infer table structures and generate optimized transformations for data warehouses and lakehouses.

Receive smart chart recommendations per dataset, with dashboards ready to export or customize.

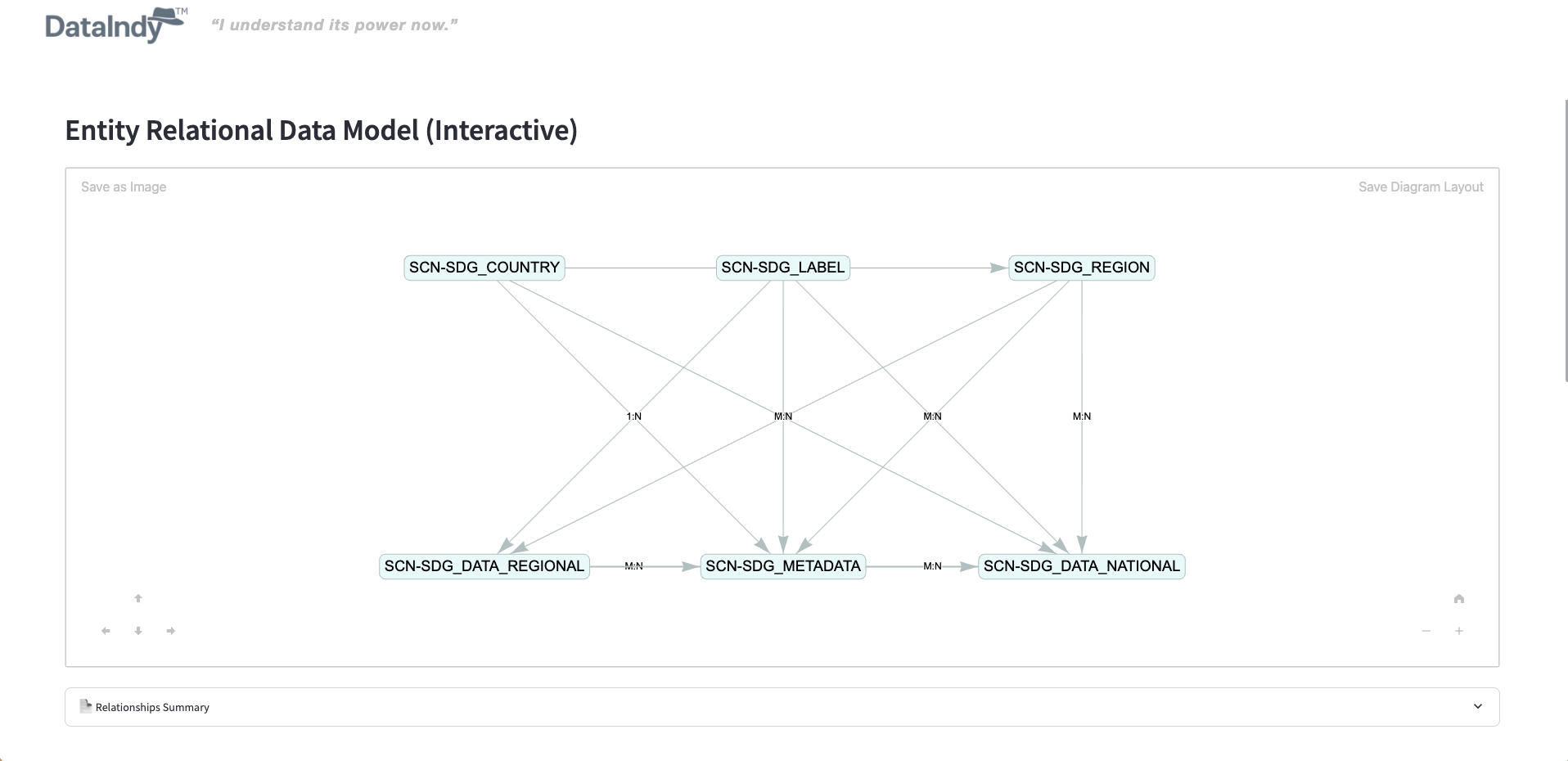
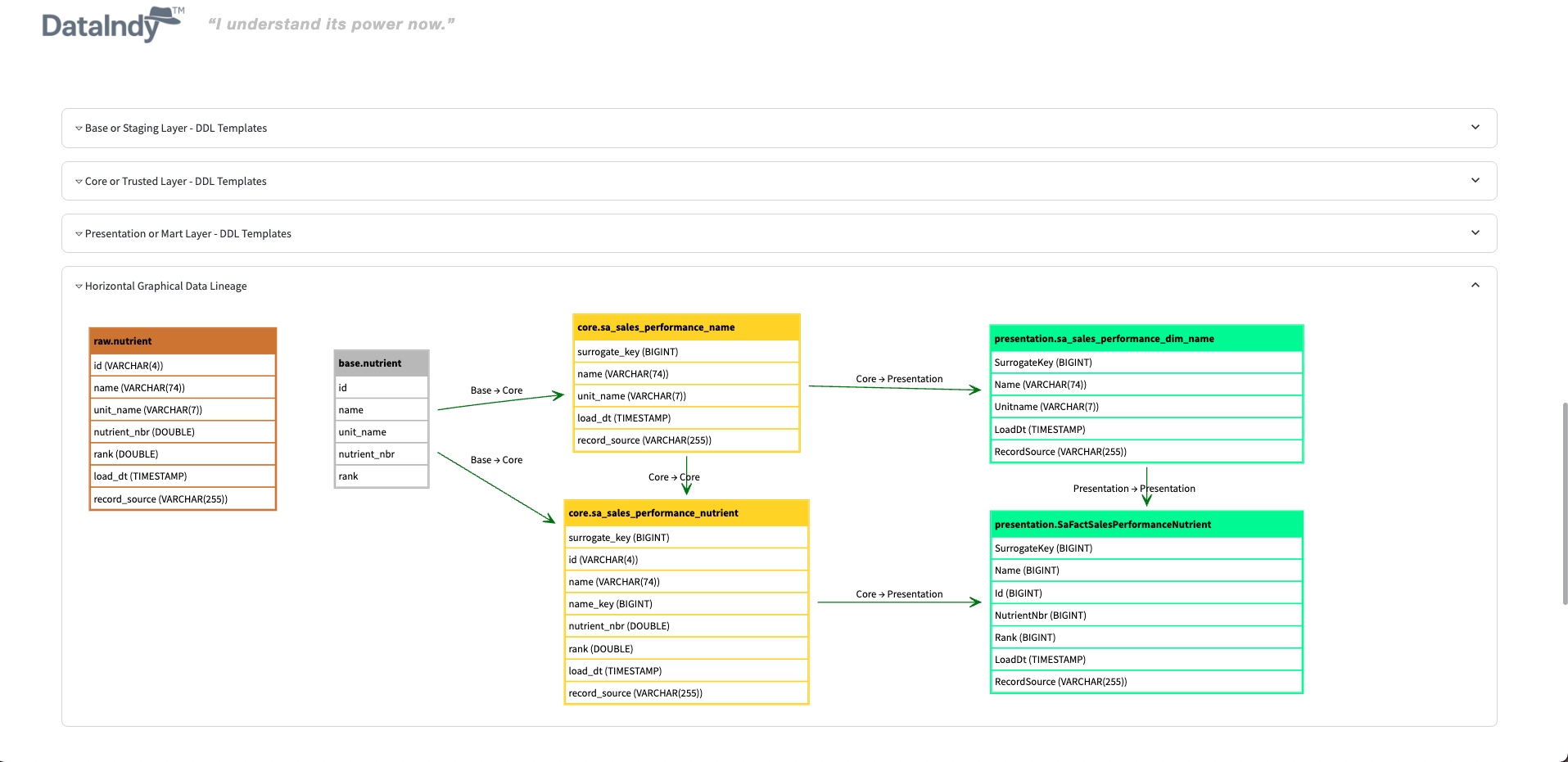
Generate ER diagrams, detect potential PII/PHI columns, and surface dataset insights—fully customizable via APIs or catalog components.
Start transforming raw data into actionable insights with DataIndy.
Fast, flexible, and designed for modern organizations.
DataIndy was built independently, with guidance and feedback from experienced data engineers, data analysts, and data scientists. It reflects real-world needs from building automated data pipelines, and analytics systems.
“I built DataIndy after repeatedly seeing teams struggle with slow, manual data workflows.
While some individual parts of the data workflow exist across separate tools.
DataIndy is the first to unify them into a single, automated system, saving time,
effort, and cost for teams.”
— Founder, based on feedback collected from teams
It analyzes your datasets (CSV, JSON files, or database tables), automatically detects relationships, and generates an interactive Entity-Relationship Diagram (ERD). You also get AI-powered descriptions and multiple export options.
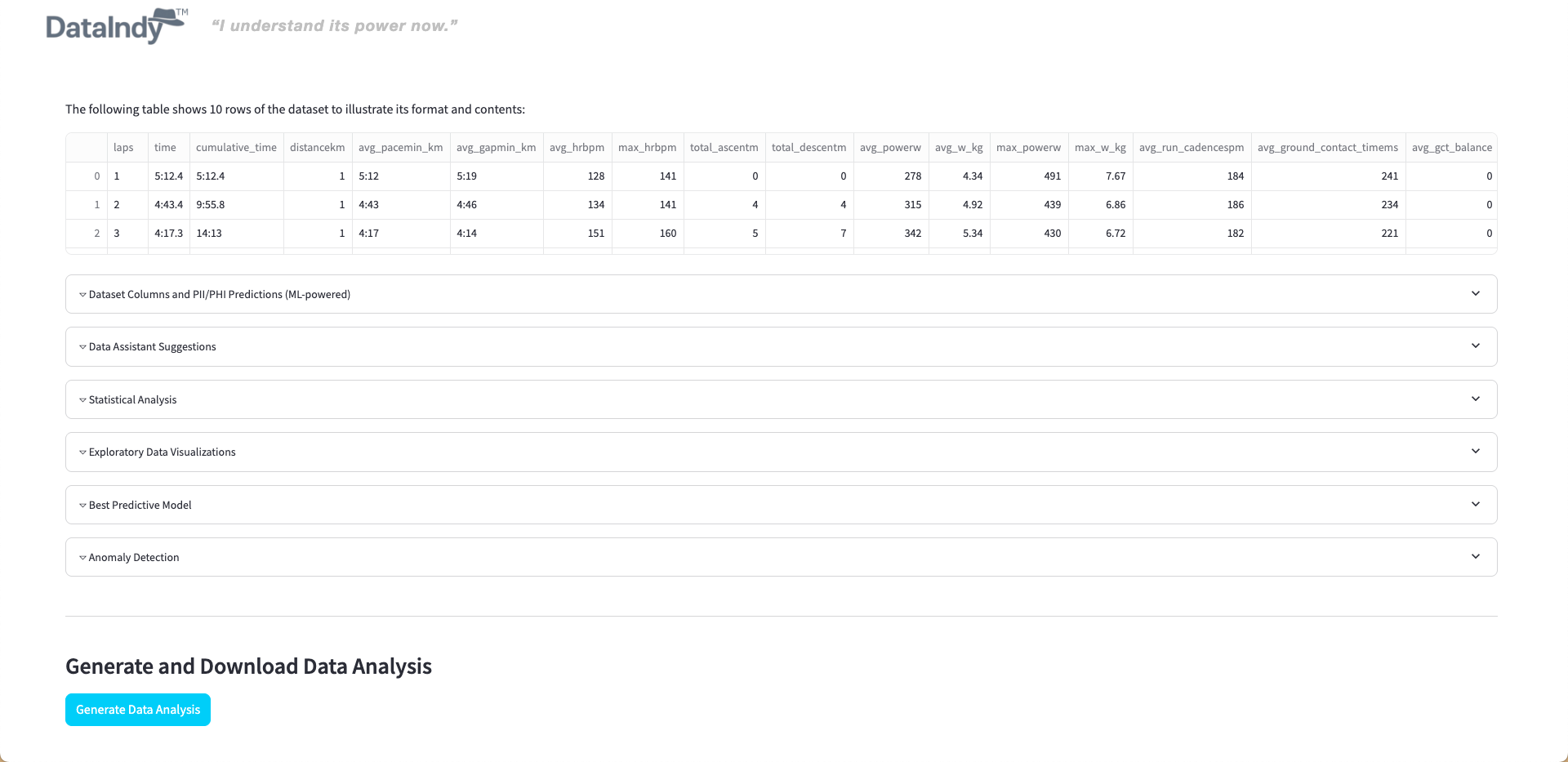
With one click, it produces a complete data analysis and generates the DDL scripts needed to build your data warehouse.
It suggests how to normalize your tables or files, across multiple database dialects.
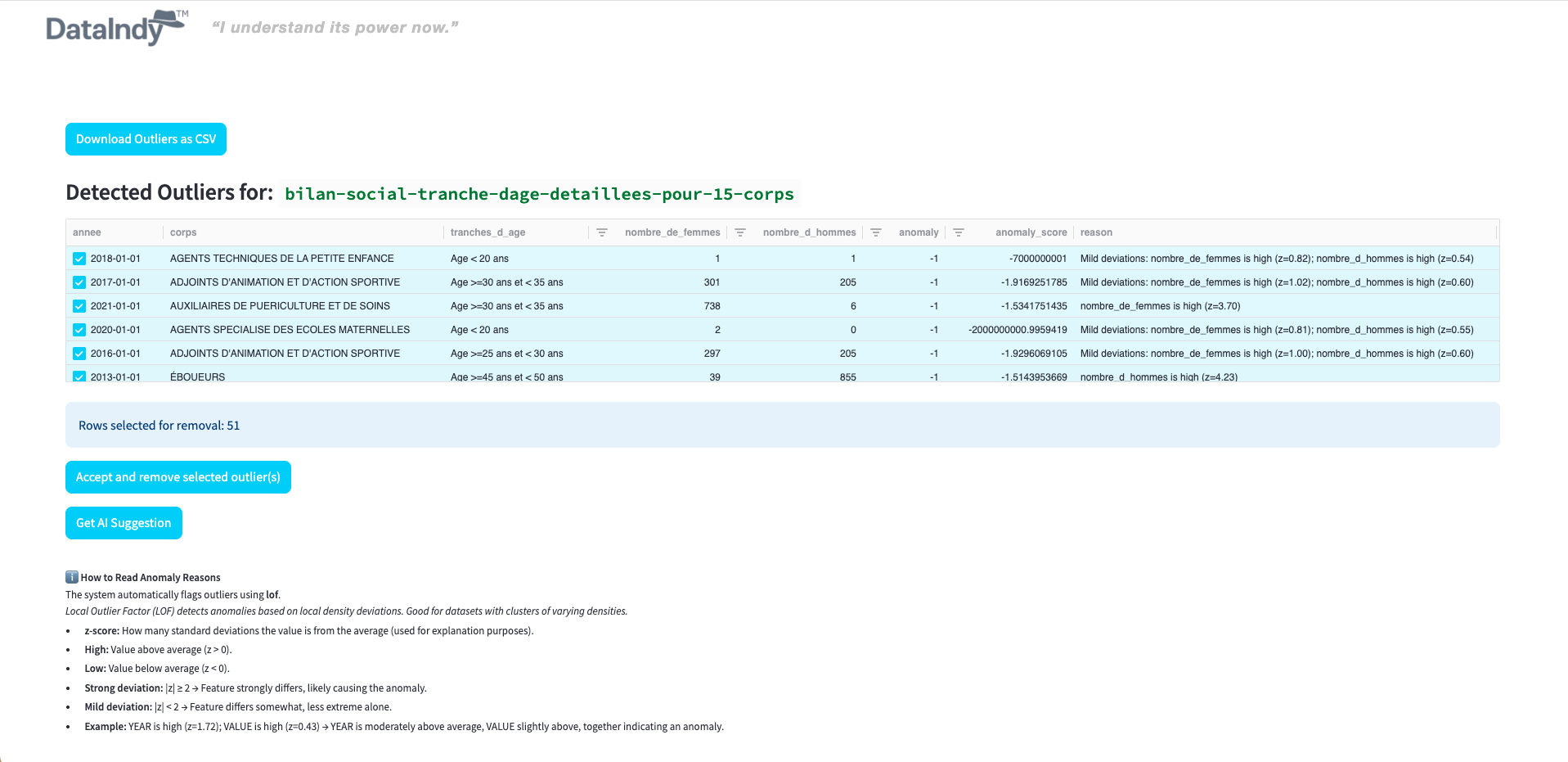
It automatically detects outliers and duplicates, helping you clean your datasets before analysis.
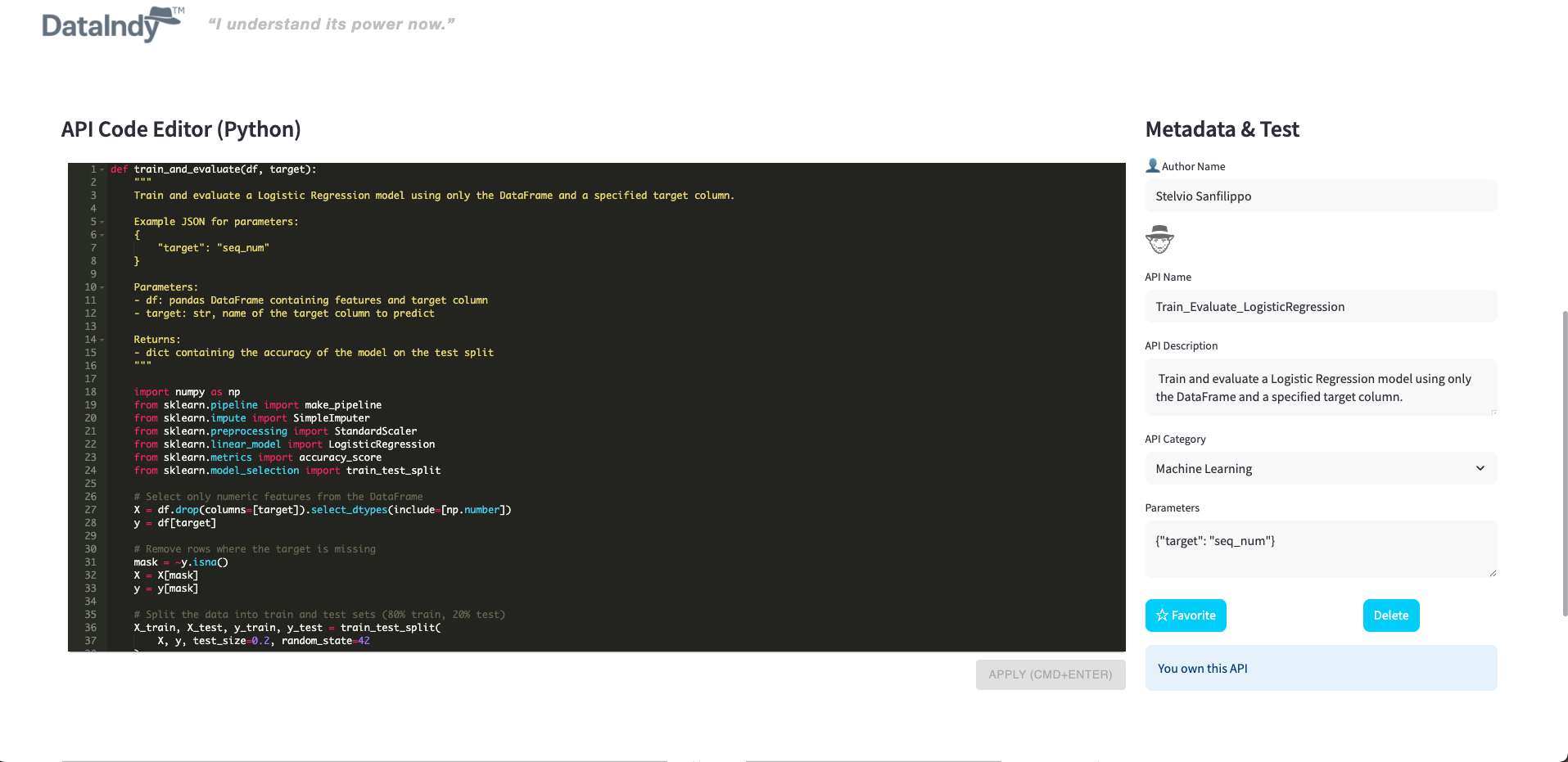
It identifies PII/PHI data using machine learning and recommends AI models per dataset column, benchmarking performance automatically.
All these functions — and many more — are seamlessly powered by AI.
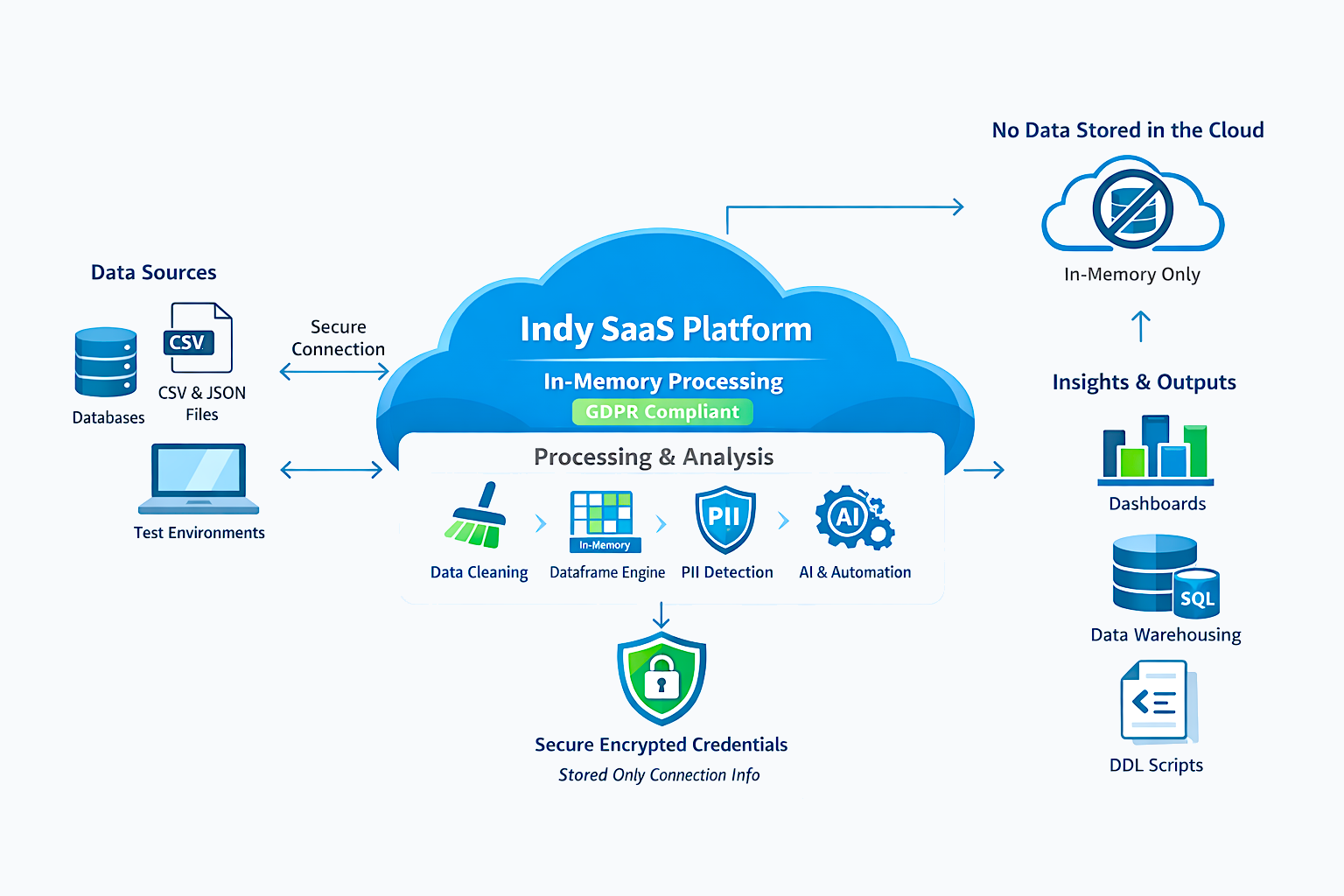
No. Indy does not store your data in the cloud. Your datasets (CSV, JSON files, or database tables) are processed online in-memory as dataframes and discarded once processing is complete.
This approach ensures full data residency and control, while still enabling advanced capabilities such as automated relationship detection, ERD generation, normalization recommendations, and data quality analysis.
Indy operates across multiple database dialects, automatically detects outliers and duplicates, identifies PII/PHI using machine learning, and generates DDL scripts and AI-powered insights — all without persisting your data.
Yes. Indy is GDPR compliant by design and follows key GDPR principles such as data minimization, security, and privacy by design.
Indy does not store or persist customer datasets. All data is processed ephemerally in-memory as dataframes and discarded after execution. The only customer data stored consists of connection credentials for test databases, which are securely encrypted at rest.
The platform supports compliance by automatically detecting PII/PHI, enforcing consistent data standards, and embedding governance controls across the data lifecycle, helping organizations meet GDPR obligations related to data protection, accountability, and risk reduction.
Unlike traditional tools that require your data to be in a database, this tool works directly with raw CSV, JSON files or tables from your databases. It uses AI to automatically detect joins and relationships, making it perfect for data discovery and rapid prototyping. With just a few clicks, you can generate a complete Data Warehouse script — no time wasted writing from scratch. You can even import the result from ERWin or other data modeling tools for further refinement or to generate a complete data model diagram.
Designed for data analysts, data engineers, consultants, data scientists, students, and small teams who need fast, affordable solutions. Quickly generate ERDs, run data analysis, create DWH/Lakehouse scripts, and perform profiling, cleaning, normalization, and more. Automate end-to-end data integration without the cost and complexity of traditional tools.
Built for enterprise as well: the platform is multi-tenant and helps standardize data products, enforce naming conventions, and manage user access with RBAC. Managers can govern multiple tenants easily, supporting modern architectures such as data factories and data meshes.
The tool is especially useful in migration projects or post-merger integrations, where it can automatically identify relationships across databases and accelerate unification efforts.
Indy connects securely to customer test databases, CSV, and JSON files. The only stored customer data are encrypted connection credentials, ensuring maximum security.
Data cleaning, normalization, PII/PHI detection, AI-powered analysis, and warehouse design are executed through a secure in-memory processing engine, allowing fast, safe, and efficient processing without touching disk storage.
Governance, GDPR compliance, and consistent standards are embedded across the entire lifecycle, without slowing down analytics or time-to-market. This ensures data quality and compliance by design.
Yes! You can export your ER diagram as a PDF for documentation or as JSON to preserve node positions. AI-generated entity summaries are included to enrich your documentation automatically.
You can also generate and export DDL scripts, making it easy to recreate the data model directly in industry-standard tools such as ERwin, IDERA, and others.
The app works best with small to medium-sized CSV or JSON files (under 50MB). For very large datasets, you might need a database integration in the future roadmap.
The base plan (Raider) is free, but comes with limited functionality and does not include exports or advanced AI — the core strengths of this tool. Premium plans unlock powerful features such as exporting data analysis, generating DWH/Lakehouse DDL scripts, and receiving advanced AI-driven suggestions.
We offer four profiles to fit different needs: Raider (free), Analyst (focused on data analysis), Indy (all features except multi-tenancy), and AdminTeam (multi-tenant with audit logs for governance).
You can explore each profile in detail inside the application after subscribing. All subscriptions are monthly, flexible, and can be cancelled or upgraded at any time.
Have questions or want to learn more about DataIndy? Fill out the form below and we’ll get back to you.